Abstract
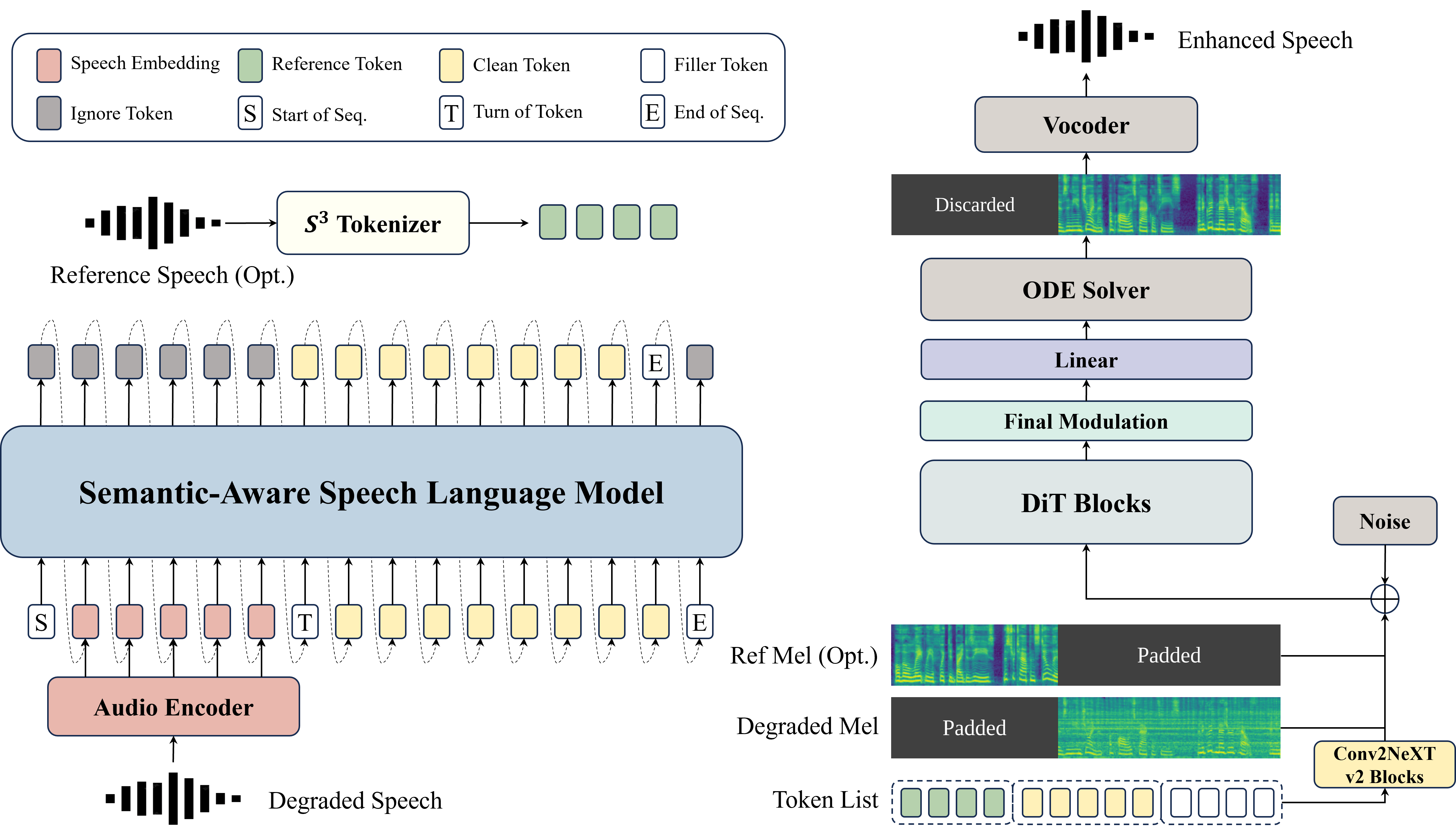
Generative Universal Speech Enhancement (USE) methods aim to leverage generative models to improve speech quality under various types of distortions. However, existing generative speech enhancement methods often suffer from semantic inconsistency in the generated outputs. Therefore, we propose SenSE, a novel two-stage generative universal speech enhancement framework, by modeling semantic priors with a language model, the flow-matching-based speech enhancement process is guided to generate semantically faithful speech, thereby effectively improving context fidelity. In addition, we introduce a dual-path masked conditioning training strategy that enables flow-matching-based enhancement to flexibly integrate multi-source conditioning signals from degraded speech, semantic tokens, and reference speech, thereby improving model flexibility and adaptability. Experimental results demonstrate that SenSE achieves state-of-the-art performance among generative speech enhancement models and exhibits a high performance ceiling, particularly under challenging distortion conditions.